Merging
假设你有一堆有上亿行的日志。此时你的老板端着咖啡杯走过来,他想知道昨天有多少个独立的 IP 地址访问了公司网站。
让我们假设这就是今天早上发生的,试试解决这个麻烦
可以想到的蛮力方法是提供一个集合 Set,并逐行遍历统计记录直到结束,然后将该集合的长度返回给用户。

可以想象到,这种方法有很多问题
- 慢,非常的慢。
- 消耗很大的内存
- 简单运算可以知道,至少需要 3.2GB 的内存!
并行
为了解决问题,你需要并行运行你的 count(distinct(ip))。
从理论上讲,这与串行方法相同。每个 Worker 协程/线程处理数据的一个子集,并维护对应 IP 地址集合。 但是,在实际操作中有一个关键问题,那就是最终仍然需要将所有 IP 的所有集合合并到一个集合中,以便确定唯一的计数。
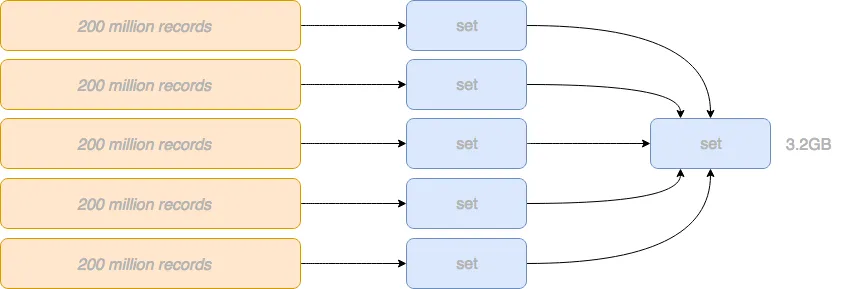
这是一个比上面的蛮力解决方案好得多的方法,但它也无法避免
- 过高的内存消耗
- 过大的带宽消耗
- 在不同的 Worker 之间操作或转移这些集合是很吃力的,尤其是考虑多个机器集群处理时
估计
仔细想想,你的老板到底是需要一个相当精确的数字还是仅仅一个大致准确的数字就够了。
在这个数量级下,对于像多少个独立 IP 地址这样的数字,如果你统计结果稍微出了点小偏差,真的有关系吗?
这正是 HyperLogLog 的亮点所在。 因为 HyperLogLog 的核心——“寄存器”仅仅只是一个字节数组。 哪怕最高的精度(16)需要 65,536 个寄存器,其所使用的内存也仅为 512KiB1
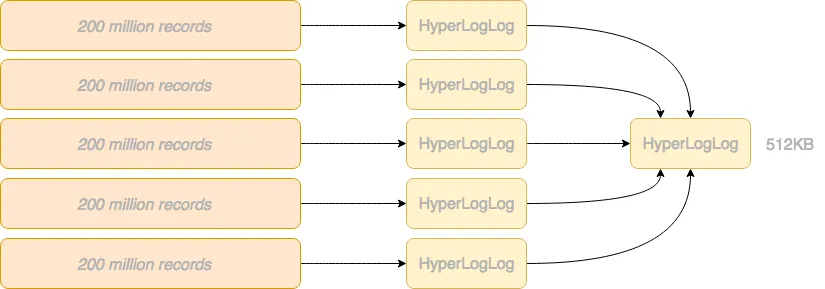
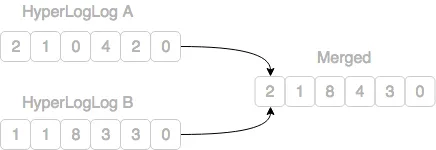
而跨节点合并 HyperLogLog 实例实现也非常简单,只是合并寄存器而已。 仅需要比较每个寄存器,并保留最大值。
然后使用合并后的实例执行计数即可。
这种实现
- 内存消耗很小
- 带宽消耗很小
- 也很块
- 非常容易并行
Footnotes
-
注意,HyperLogLog 的一些实现使用了稀疏数组表示的寄存器,这节省了更多的内存。请见HyperLogLog++ [return]